Finding rows on a table is straight forward when filtering on columns, but what if you want to find duplicate data.
Let’s say I have a table that represents parents and children. The key to the table is the parent guid which is unique. Each row also has a child guid key that unique to the child, but is not unique in the sense that the child could have accidentally been added to the table twice.
Let’s look at the table:
SELECT * FROM parent_child

As you can see, David Doe was entered twice. How do you narrow your query to group like rows?
SELECT CHILD_GUID, FIRSTNAME, LASTNAME FROM parent_child GROUP BY CHILD_GUID, FIRSTNAME,LASTNAME
The SQL statement is selecting those columns that would be unique among duplicated rows. These columns are then added to a ‘GROUP BY’ clause to group like rows together. As you can see above, David Doe is in the table twice. We want to see David Doe once. The results are as follows:
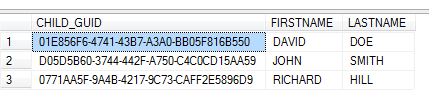
But now you only want to return rows that are duplicate only. This is where the ‘HAVING’ clause comes in to play. By adding HAVING COUNT(*) > 1, only rows that are duplicated more than once will return in the result set.
SELECT CHILD_GUID, FIRSTNAME, LASTNAME FROM parent_child GROUP BY CHILD_GUID, FIRSTNAME,LASTNAME HAVING COUNT(*) > 1

Now we see only the duplicate records, but you can take it a step further by saying show me the duplicates of the duplicate records. By placing the latter SQL code into a temporary table, you can then select the temporary table and join the original table to it where the child guid’s are equal as follows:
DECLARE @ParentChild TABLE
(child_guid uniqueidentifier, FIRSTNAME varchar(50), LASTNAME varchar(50))
INSERT INTO @ParentChild(child_guid, FIRSTNAME, LASTNAME)
SELECT CHILD_GUID, FIRSTNAME, LASTNAME
FROM parent_child
GROUP BY CHILD_GUID, FIRSTNAME,LASTNAME
HAVING COUNT(*) > 1
SELECT parent_child.PARENT_GUID, temptable.child_guid,
temptable.FIRSTNAME, temptable.LASTNAME
FROM @ParentChild temptable
LEFT OUTER JOIN parent_child
on parent_child.CHILD_GUID = temptable.child_guid
The results are as follows:
